This is a brief summary of paper for me to study and note it, Hierarchical Attention Networks for Document Classification (Yang et al., NAACL 2016).
They propose hierarchical attention Network which mirrors the hierarchical structure of a document(words from sentences, sentences from a document)
They created the repersentation for a document using words and sentences vectors with bidirectional GRU as follows.
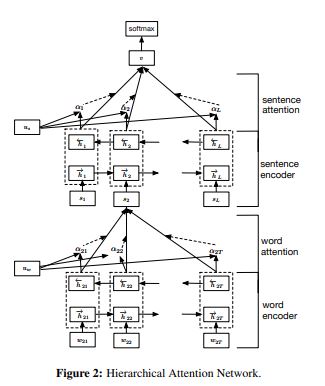
Their idea is simple and used Bidirecational GRU to get contextual vector around a word \(W_t\) in sentence.
it is called sentence vector then they repeated with sentence vector and another bidirectional GRU once again.
Also they pay attention to words and sentences with context vector on each level.
Becaus the importance of words is highly context dependent.
Let’s see the word attention
\[h_{it} = [\overrightarrow{h_{it}}, \overleftarrow{h_{it}}]\]\(h_{it}\) which summarizes the information of the whole sentence centered around \(W_{it}\)
\[a_{it}(s) = \frac{exp(u_{it}^{T}u_w)}{\sum_{t}exp(u_{it}^{T}u_w)}\] \[s_i(s) = \sum_{t}a_{it}h_{it}\]They first feed the word annotation \(h_{it}\) through a one-layer MLP to get \(u_{it}\) as a hiden representation of \(h_{it}\), then they measure the importance of the word as the similarity of \(u_{it}\) with a word level context vector \(u_w\) and get normalized importance weight \(a_{it}\) through a softmax fucntion.
After that, they get a weighted sum of the word annotations based on the weights.
In here, the context vector \(u_w\) can be seen as a high level representation of a fixed query over the words like that used in Memory network.
So the context vector \(u_w\) is randomly initialized and jointly learned during the training process.
In the case of sentence level, it is the same from the process above.
For classifier, they used cross-entropy to reduce the negative log-likelihood of the correct labels as training loss.
Let’s see the baseline they prepared to compare with their result.
- Linear methods : Linear methods use the constructed statistics as features. A linear classifier based on multinomial logistic regression is used to classify the documents using the features.
- BOW and BOW+TFIDF: The 50,000 most frequent words from the training set are selected and the count of each word is used features.
- Bow+TFIDF: as implied by the name, uses the TFIDF of counts as features.
- n-grams and n-grams+TFIDF: used the most frequent 500,000 n-grams (up to 5-grams). Bag-of-means The average word2vec embedding is used as feature set.
- SVMs: SVMs-based methods are reported including SVM+Unigrams, Bigrams, Text Features, AverageSG, SSWE. In detail, Unigrams and Bigrams uses bag-of-unigrams and bagof-bigrams as features respectively.
- Text Features are constructed, including word and character n-grams, sentiment lexicon features etc.
- AverageSG constructs 200-dimensional word vectors using word2vec and the average word embeddings of each document are used.
- SSWE uses sentiment specific word embeddings
- Neural Network methods: The neural network based methods are reported.
- CNN-word: Word based CNN models
- CNN-char: Character level CNN models
- LSTM takes the whole document as a single sequence and the average of the hidden states of all words is used as feature for classification.
- Conv-GRNN and LSTM-GRNN : it also explores the hierarchical structure: a CNN or LSTM provides a sentence vector, and then a gated recurrent neural network (GRNN) combines the sentence vectors from a document level vector representation for classification.
Reference
- Paper
- How to use html for alert